More on parallel gradient
Motivation
Here, we present an advanced method for discretizing the parallel gradient, based on a coordinate-free representation, where areas are mapped instead of individual points. Therefore, this approach is more intuitive and performs better in situations with significant map distortions. The scheme was firstly introduced in A. Stegmeir et al., Comput Phys. Commun. 213:111, (2017), where you can also find verifications and illustrative examples.
Coordinate free represenatation
We start with the coordinate free representation of the parallel gradient: where is an arbitrary volume parametrisation which continuously shrinks to zero with , i.e. .
For clarity and compact notation in the following, we introduce the staggered grid index . We mimic the expression on the discrete level according to the sketch illustrated in the figure below: where we choose the finite flux box volumes such that only the surface integrals at the toroidal ends remain. These surface integrals are retained on the continuous level within the poloidal planes and .
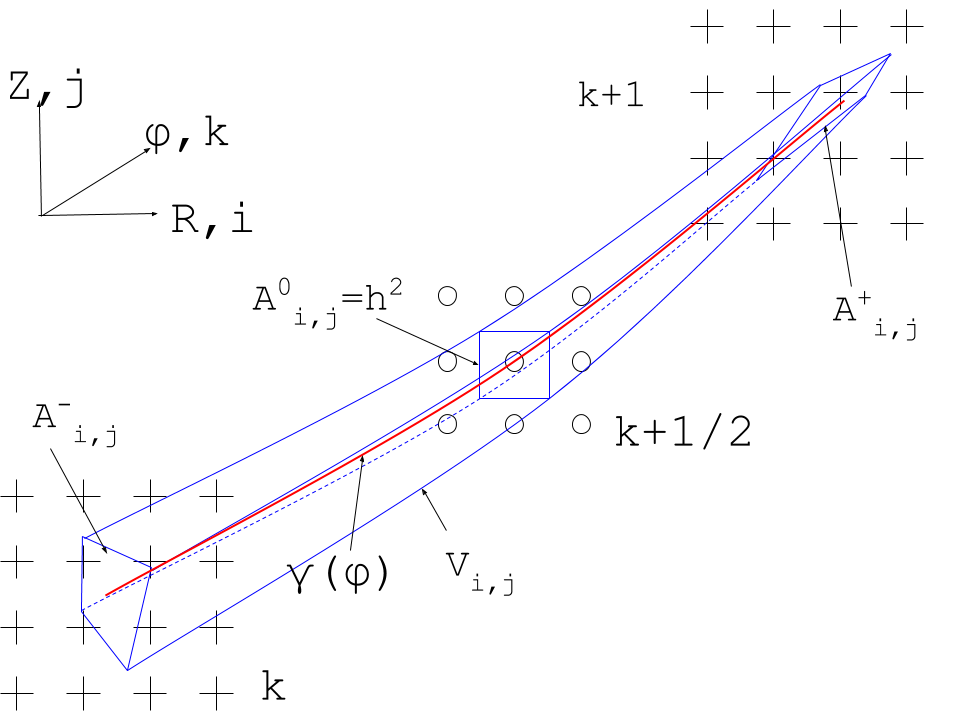
Sketch of the integration scheme for the parallel gradient: Blue represents the finite flux box being integrated, and red indicates the central field line.
Prefactor in eq. ():
The pre-factor in eq. () is defined as where represents the cross-sectional area of the flux box. This expression can be simplified by the fact that magnetic flux is conserved, and therefore: This leads to: Therefore, the prefactor can be easily computed from the magnetic field line length along the central chord of the flux box (see field line tracing).
Quadrature in eq. ():
Finally, we need to numerically integrate the surface terms in equation (), which are located within the poloidal planes. To achieve this, we divide the area of interest into subcells or quadrature points, where (X \ge 0) is an integer parameter, and are the subcell indices (see figure below): where
By utilizing the conservation of magnetic flux again (see eq()), we express the toroidal magnetic flux in the mapped areas in terms of the flux in the base area. We apply interpolation to compute: While increasing the parameter results in a longer map construction time, it has little effect on the performance of the parallel gradient evaluation via matrix-vector products. This is because the size of the interpolation stencil, which ultimately determines the matrix's sparsity, is only weakly influenced by .
Additionally, various quadrature options are available. For example, the size of the interpolation stencil can be fixed, or alternative methods such as Gaussian quadrature, where subcell division differs, can be used.
Finally, for the discrete parallel gradient simplifies to: which represents a straightforward finite difference along the magnetic field lines, using the field values at the mapped locations relative to the base point.
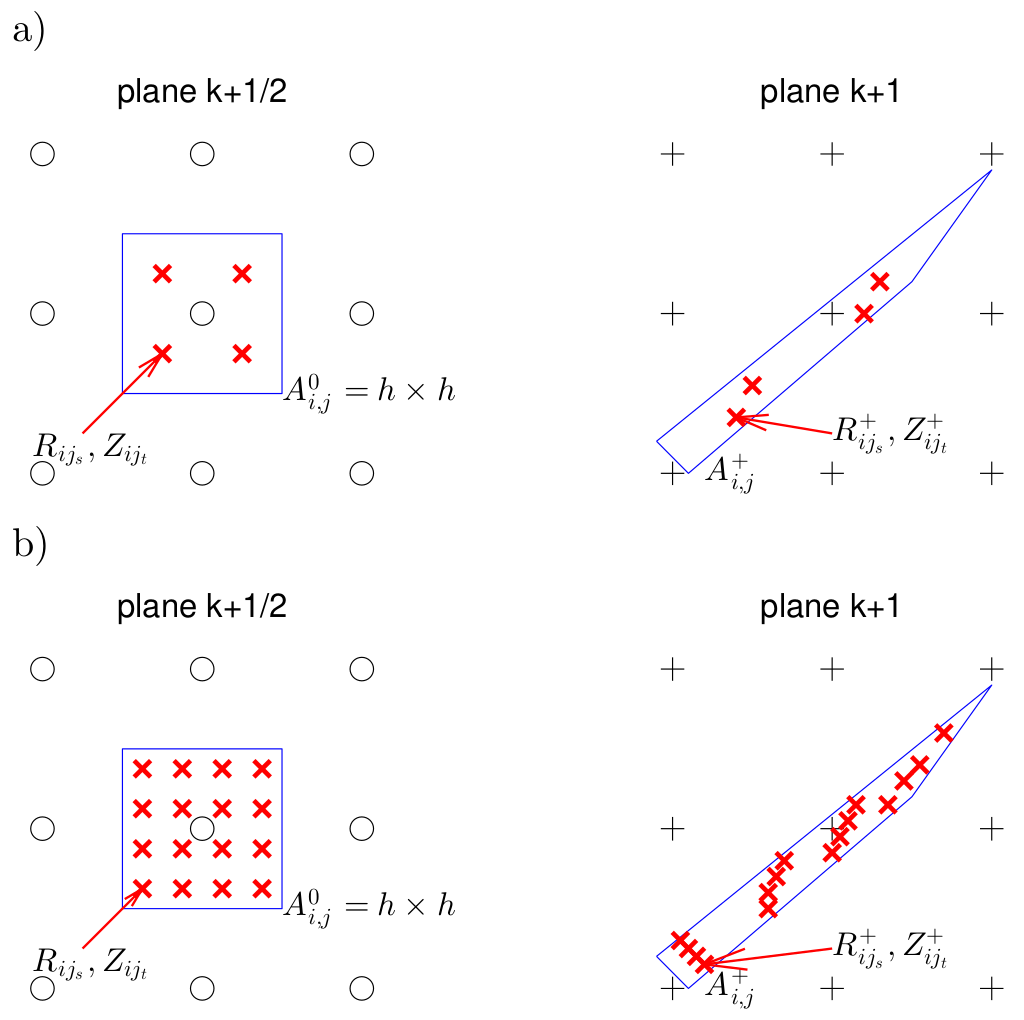
Sketch for integration via splitting into subcells for X = 1 (a) and X = 2 (b). The cross section of at plane (left) and of at plane (right) are illustrated. The cross section of at follows analogously.